
Recuerdo con cariño aquella época en la que Intel y AMD se peleaban por lograr crear la primera CPU capaz de llegar a 1 GHz de frecuencia de reloj. Aquella carrera la ganó (¡sorpresa!) AMD, pero hasta que se produjo aquel hito el ritmo era vertiginoso. O eso nos parecía, porque con la IA el ritmo de lanzamientos está absolutamente desbocado.
Vaya semanitas llevamos, queridos lectores. Veamos:
- 27 de enero: Kimi.ai lanza Kimi J2.5
- 5 de febrero: Anthropic lanza Claude Opus 4.6
- 5 de febrero: El mismo día OpenAI lanza GPT-5.3-Codex
- 5 de febrero: Kuaishou lanza Kling 3.0
- 12 de febrero: Z.ai lanza GLM-5
- 12 de febrero: ByteDance lanza Seedance 2.0
- 12 de febrero: MiniMax lanza MiniMax 2.5
- 16 de febrero: Alibaba lanza Qwen3.5-397B-A17B
- Próximamente: DeepSeek v4, ¿Llama?, Gemini 3.1, ...
El ritmo es absolutamente frenético, y los LLMs que hace unos meses semanas parecían ser fantásticos ahora ya no lo son tanto. Las nuevas versiones de esos modelso de lenguaje no paran de evolucionar, y las empresas de IA siguen ofreciendo novedades de forma constante. Casi mareante.
Eso, por supuesto, tiene su lado bueno y su lado malo. Terminamos 2025 con cierto hastío ante una IA que prometía mucho pero no acabó de cambiar apenas nada. Solo a finales de año se vio una revolución palpable con esa combinación espectacular que formaban Claude Code y Opus 4.5.

El binomio de Anthropic maravillaba a los desarrolladores, que por primera vez parecían estar de acuerdo a la hora de declarar que con este tipo de plataforma podían pedirle a la IA lo que uno quisiera, que ella te lo programaba del tirón y casi siempre sin problemas. Por supuesto en ese discurso había algo de exageración, pero ciertamente la capacidad de Opus 4.5 y el grado de autonomía y versatilidad de Claude Code parecieron marcar un punto de inflexión.
Luego llegó OpenClaw y eso ha vuelto a disparar las expectativas por los agentes de IA, pero en paralelo estamos viendo una auténtica fiebre de lanzamientos de nuevos modelos de IA generativa, tanto en vídeo (Kling 3.0 y sobre todo Seedance 2.0 han sido fenómenos virales en si mismos) como en texto/código. Y con cada nuevo modelo, la promesa de que el rendimiento va superando a la generación anterior. Al menos, claro, en los benchmarks.
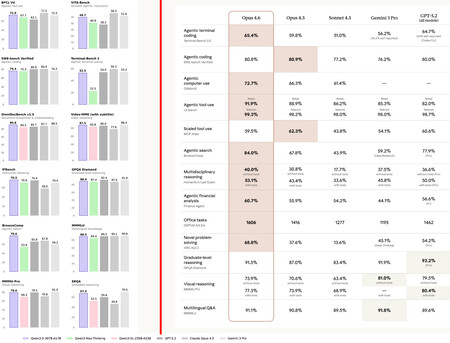 A la izquierda, benchmarks internos de Alibaba para Qwen3.5. A la derecha, los de Anthropic para Opus 4.6. Cada uno se compara con quien considera oportuno.
A la izquierda, benchmarks internos de Alibaba para Qwen3.5. A la derecha, los de Anthropic para Opus 4.6. Cada uno se compara con quien considera oportuno.Esos gráficos de barras de la imagen superior se han convertido en una constante, sobre todo cuando quien lanza el modelo es una empresa china. Si el que lanza es OpenAI, Google o Anthropic, lo que se prefiere son las tablas. Sea como fuere, el resultado siempre nos lleva a lo mismo: cada modelo es mejor que su predecesor y, normalmente, que muchos de la competencia.
Fatiga de las suscripciones... de IA
El problema de esto es que esa carrera no parece acabar nunca, y un modelo que parece fantástico hoy no lo es tanto mañana, cuando su competidor puede superarle por poco, pero además puede ser bastante más barato —los modelos chinos lo suelen ser— u ofrece otras ventajas como mayores ventanas de contexto para que podamos introducir textos más y más largos —por ejemplo, grandes repositorios de código— como parte del prompt.
Y claro, eso plantea un problema para los usuarios. Si Opus 4.5 era tan bueno, uno podría apuntarse al plan Pro o al Max y pagar un año por adelantado, pero eso es a priori arriesgado, porque aunque tendrás acceso a nuevos modelos cuando los saques, habrás dedicado tu inversión en suscripciones de IA al modelo de Anthropic sin tener ya tanto margen para probar los de los rivales.
Aquí se imponen las suscripciones cortas: suscribirse a un modelo un mes para poder tener margen de maniobra por si quiero probar otro modelo al mes siguiente (o probar dos o tres modelos el mismo mes, que también es un caso común).
Los precios de las suscripciones a servicios de IA no son además facilitadores de esas pruebas múltiples. Lo normal es pagar 20 euros por una suscripción de un mes, y aunque los modelos chinos suelen ser bastante más baratos, también suelen estar un escalón por detrás en capacidad si uno necesita las máximas prestaciones.
Pero aquí se repite una y otra vez el problema: si me suscribo ahora a GPT-5.3-Codex, que todo el mundo dice que es fantástico, ¿cuánto tiempo lo pago, un mes? ¿O me suscribo además a GLM-5 para probar, y ya el mes que viene probaré Opus 4.6 y MiniMax 2.5?

Todas esas decisiones son difíciles porque la percepción de cada modelo depende de cada usuario. Cada uno de ellos tiene sus necesidades, su presupuesto y sus propias experiencias con cada modelo, así que por mucho que los benchmarks digan una cosa, con los modelos de IA nos está pasando como con los vinos: por mucho que nos digan que uno es mejor que otro, nosotros los percibimos de forma muy personal.
Y ese avance frenético hace que además se haya recuperado esa expectativa por modelos que realmente marcan la diferencia. El vibe coding no es perfecto, pero cada vez resuelve mejor nuestras necesidades, y lo mismo ocurre con los agentes de IA como OpenClaw, que con sus luces y sus sombras demuestran que ese futuro en el que tengamos un empleado de IA —aunque al principio pueda ser algo torpe— funcionando 24/7 no parece estar tan lejos.
Son tiempos vertiginosos y fascinantes para la IA. Otra vez.
Imagen | Mohammad Rahmani
via Robótica e IA - Xataka https://ift.tt/fczQykR
No hay comentarios:
Publicar un comentario